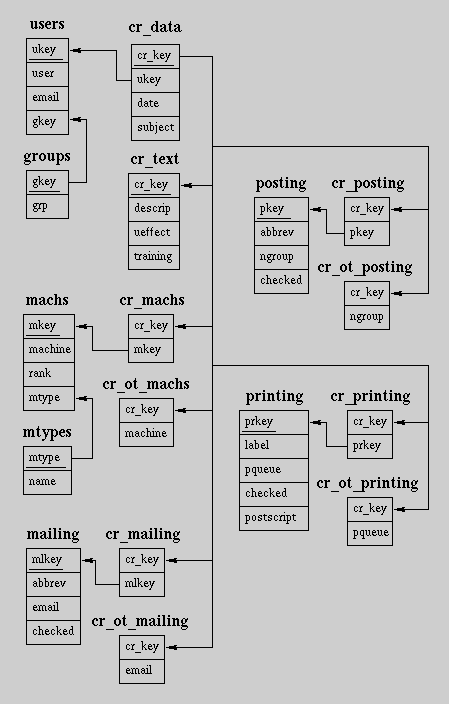
Figure 1 - System Change Report Database Schema
Nem W. Schlecht
Information Technology Services
North Dakota State University
schlecht@plains.nodak.edu
The idea that every faculty & staff member should learn and write
HTML for the delivery of their departmental and class information is
unreasonable. Most have attended seminars, been given fancy editors and
technical handouts, and had other resources at their disposal. They may
attend or use these resources with high hopes, but many are still
disappointed and frustrated. Many departments want to solve this problem,
but as in many small colleges and universities, funding is somewhat
lacking. This paper describes the structure of a system which implements a
solution to the above problems, with little strain on faculty or most staff
or on their departmental budget.
First, a brief, non-technical introduction will be given, with a
review of some similar implementations with various delivery methods
(Gopher, newsgroups, etc.) and why these methods do not address all of the
current problems and needs of departments. Next, a description on the
usage of free software packages and how to obtain and implement them is
addressed.
This is followed by a discussion of the underlying relational
database implementation and some possible database schemas to use in that
database. This database is the backbone of the organizational structure
that is needed to solve the above problems. Then, we look into the ways
the above packages can be integrated to work together in providing an
information solution that is both easy to update and to obtain current,
valid information from. An example of some working models as well as an in
depth analysis of these models and some of the problems with them will
conclude the technical discussion.
The paper concludes with a exploration of how far this model can be
taken and what options there are to expand its capabilities and
functionality.
Introduction
Computer science, as a profession, deals with data. We collect it, examine it, do statistical analysis on it, give that data to someone else, etc. With the explosion of the Internet, we now have a lot more data that we are moving around. A lot of us have set up mail filters to handle the hundreds of e-mail messages we receive each day. We browse the Web looking for information for our research or maybe to find out what is going to be on T.V. at 3:00 in the morning. Unfortunately, a lot of us are having either a hard time keeping up with all this data, or we work around the clock trying to stay ahead of the game. Before the creation of the web, the three major information exchange forums were E-mail/Listserv, Net News and Gopher. I'm sure all of us are still using and will continue to use E-mail, as well as I'm sure most of us either are or have been signed up to at least one Listserv list. Although effective, E-mail and Listserv take up a lot of bandwidth and disk space - each user in a list gets a copy of the message. Net News was favorable because it had two major enhancements to Listserv. First is the idea of an information thread. Somebody could make a statement, someone else would add something, another person would disagree, and the first person would explain their statement further. Any person could easily read the entire thread of discussion and understand what all was happening. They did not have to search through a hundred mail files to find out what everybody said. Net News also had central storage, reducing both the amount of network traffic and disk space needs associated with such discussions. Lastly, Gopher, or the text-only web, which was the first application with an easy to use fetch interface. Instead of sending data out to everybody, they had to come to them to get it.
All three have advantages and disadvantages, but they all suffer from the lack of being dynamic. Gopher had the ability to run a program or fill out a simple form, but its capabilities were severely limited. Today, with Javascript, Java, Perl, and a host of other specialized applications, programs, and languages, information sources can be very dynamic. Instead of writing static or mainly static HTML pages, we should concentrate on the creation of page templates with database backends. Once we have our template, we can easily update the underlying information and make it instantly accessible to web visitors. Alternatively, we can update our template and in an instant we can have a new 'look and feel' to our web page. Also, searching for specific data is easily done, leaving little need to create and maintain a search engine. Dynamic web delivery has been going on for a long time now with server side includes allowing the current time or the last time a certain page was modified automatically being sent to the user. This paper discusses taking this to the next level and making a more of your web pages dynamic.
Free Software
Contrary to what many I.T. managers may say, free software is a viable solution to many problems, and they are actually the preferred solution by many systems programmers such as myself. Also, many departments that have a tight budget will probably have to venture into the 'free' market whether they want to or not. A lot of free programs actually have excellent capabilities and support. MySQL, mentioned below, is an excellent example of this. For implementing a web and database integration solution, I feel UNIX is the best operating system for the job. It is robust, usually faster, and usually much more stable than Windows or Windows NT. Also, there are free versions of UNIX available, such as Linux or FreeBSD. For CGI scripts, Perl is an excellent choice. I prefer to write my programs in an object oriented fashion, where applicable. Perl has O.O. features as well an interfaces into countless other extensions. For web and database integration, there are 2 modules that are crucial for this. The first of these is the CGI module, which allows for easy web form creation and processing. The other is the DBI module (Database Independent Interface), which provides a cross-database Perl API. The DBI module requires an accompanying DBD (Database Driver) module. There are DBD modules for a host of commercial databases, including Oracle, Sybase, Informix, Ingres, IBM's DB2, as well as others. The free databases that it supports include MySQL, mSQL, and PostgreSQL. Of these, I prefer MySQL, which is supported on a wide variety of UNIX platforms as well as on Windows NT. It makes use of threads for better performance compared to mSQL and PostgreSQL. PostgreSQL has more features, but is slower due to the overhead in managing those features. mSQL is the slowest and has the least number of features, but is nice, lightweight, and may be the best solution on slower hardware. For a web server, I use Apache, which is used by roughly half of the web servers on the Internet. It has a rich feature set, but is not so bloated as to cause system performance degradations. Also, Apache has the ability to load modules into it to extend its functionality. For example, there is a Perl module which allows the web server itself to execute Perl code without having to fork off an additional process.
One thing to keep in mind is that with Perl and the DBI module and DBD modules, pretty much any web server and database can be used. If you want to start out using MySQL and then later migrate to Oracle, you shouldn't have too much trouble in either moving your tables and data or in updating your Perl scripts. The same thing is true if you start out using Apache and decide later to start using Netscape's Enterprise web server. Also, all of the above mentioned free databases are implemented in a client/server manner. Therefore, if you want to run your web server on one machine and have your relational database on another machine, you shouldn't have any problems.
There are other solutions that I have seen implemented other than Perl and using the CGI & DBI modules. Another favorite one is using PHPFI, which is a pseudo-Perl language. It is mSQL and MySQL aware and the PHPFI code is inserted directly into your HTML files and parsed with either a CGI script or by an Apache module. As always, programming in C or C++ is an option. Most databases have a C client library and API that Perl or PHPFI use anyways for their database connections.
Relational Databases
Why use a relational database? Why not a 'flat text' file or some other type of file? First, is speed. Even mSQL, the slowest of the free databases, will enhance your searches dramatically. Next is the concern of file locking. Many web applications today are completely ignorant of the fact that there may be multiple copies of themselves running. Without proper file locking, files get corrupted, data is lost, or programs will deadlock and crash or never exit. Relational databases are usually programmed from the bottom up to handle multiple requests at the same time properly. Another problem of flat files and other files is the fact that searching them or changing them is often a very tedious and long process. Many of us have run across a tab or colon delimited file and found that manipulating a certain 'column' of data required a lot of extra code to do splitting and joining of the data. With a relational database, column searching and updating are easy. Finally, although it is sometimes a pain, normalizing your data to be inserted into a relational database makes your reexamine your goals and your data. By going over what data you are working with and what you want to do with it, you will probably gain an intimate understanding of the data you are working with and be able to make additional tweaks and optimizations that you would have otherwise overlooked.
Designing a relational database schema is pretty easy if you're not too concerned about 'normalization'. When you normalize your data, you remove repetitive large data samples and replace them with unique keys. For example, in the schema example below [Fig. 1], there are no users listed in the cr_data table. Instead, each user is assigned a unique numerical identifier in the users table, and that id is stored in the cr_data table instead. We have now changed a 20 to 30 byte name into a single byte. For small tables, this doesn't make much sense, since it adds an additional burden onto you to always have to do a table join. However, on large tables, you can save megabytes of disk space rather easily by normalizing your data in such manners. Searches will also be quicker, on any field in the table, since less information will have to be copied from disk to memory to examine it.
Database Schema Example - System Change Report
This is an example of the normalized database schema used in the "System Change Report", a web application that I've developed for tracking changes to machines within my organization. I'm not sure if it's normalized to the '5th level' or not, but it's pretty complex. In doing lookups for a certain change report, 10 queries are done! However, those 10 queries take only fractions of a second to complete.
Integration
Now for the complex (yet most interesting) problem. You've got your
web server hardware all set up, installed Apache, Perl, and MySQL or some
other database and you've already set up your tables. What now? Well, we
have to get your web server running Perl CGI scripts which will access your
relational database. To do this, we will take advantage of the DBI (and
DBD) and CGI modules. These modules, as well as a host of other Perl
modules are available on CPAN (Comprehensive Perl Archive Network) sites.
For a list of CPAN sites, go to http://www.perl.com/CPAN (no trailing
forward slash!). I'm not going to go into great detail on what these
packages can do for you. They all come with man pages and usually with
extensive examples. I will, however, give the source code and description
of 2 simple Perl scripts that make use of them.
Simple Perl DBI Example
The following script is the equivalent to a DBI 'hello world' program.
It loads the MySQL DBD (database driver), uses it to connect to the
'sccs' database on the machine that it is running (localhost), and
uses the username 'sprafka' and the password 'Iam#1moM'. Then
it makes a simple SQL query, reports the number of rows, and prints out the
query results as tab delimited text.
#!/local/bin/perl
use DBI;
my($dbh) = DBI->connect( "dbi:mysql:sccs:localhost", 'sprafka', 'Iam#1moM' );
my($sth) = $dbh->prepare("select * from participants");
$sth->execute();
print $sth->rows, " rows returned\n";
my(@row);
while (@row=$sth->fetchrow()) {
print join("\t", @row), "\n";
}
$sth->finish();
$dbh->disconnect();
Simple Perl DBI & CGI Example
This next short script queries a database like the previous example, but it also creates an HTML form as well. This program would be run as a CGI program from a web server. As a part of this, we need more information about our database table. Let's say the the 'participants' table contains 2 fields or columns. First, pkey, which is a simple, unique (for this table), numeric identifier. And secondly, pname, which is a 40 byte (character) field containing the name of the participant. Here is the SQL statement for MySQL used to create this table:
CREATE TABLE participants (
pkey tinyint(3) unsigned DEFAULT '0' NOT NULL auto_increment,
pname char(40),
PRIMARY KEY (pkey)
);
We create an instantiation of a CGI object and place it in $q.
Then we print out an HTML header (usually "Content-type:�text/html").
Next, we call start_html(), which sets the title and prints the
<HTML>, and <BODY> tags. Then we print out a nice banner in an
<H1> tag. Notice that I've removed the line that tells us how many
rows were returned from our SQL query, since we're not really interested in
that any more. Also notice that I'm now doing something different in the
while() loop. I'm assigning the value of the first returned field,
in this case pkey, making it the key in an associative array, and
giving it the value of the second field, in this case pname. I'm
doing this because I want to pass the value of pkey to the form
processor and not pname. That way, the form processor can do a fast
lookup on pkey and not a slow lookup on pname. Now that we
know all of the participants and their keys, we make sure that the keys are
in numerical order (we could have done this in the SQL statement), and
assign those keys to an array, @pkeys. We'll need this array later.
Now we call start_form(), and pass it the usual form information,
although it looks a little different. Now for the pop-up menu. After we
print a short identifier, we call popup_menu(). The first argument,
name, is obviously the name used in referencing this menu in the form
processor. The second argument, values, is given a reference to an
array that contains all of the possible values that will be sent to the
form processor. The last argument, labels, is given a reference to
an associative array that maps all of the possible values to labels that
will appear in the actual menu that the user sees in the web form. We end
the script with a submit button and the appropriate calls to print out
ending tags like </FORM> and </BODY>.
#!/local/bin/perl
use DBI;
use CGI;
my($dbh) = DBI->connect( "dbi:mysql:sccs:localhost", 'sprafka', 'Iam#1moM' );
my($q) = new CGI;
print $q->header();
print $q->start_html(-title => "SCCS Registration");
print $q->h1("SCCS Registration"), "\n";
my($sth) = $dbh->prepare("select * from participants");
$sth->execute();
my(@row);
my(%participants);
while (@row=$sth->fetchrow()) {
$participants{$row[0]}=$row[1];
}
$sth->finish();
$dbh->disconnect();
my(@pkeys) = keys(%participants);
@pkeys = sort { $a <=> $b } @pkeys;
print $q->start_form(-action => 'procsccs.cgi', -method => 'post');
print "Select your name:\\n";
print $q->popup_menu(-name => 'reg_participants',
-values => [ @pkeys ],
-labels => \\%participants
), "\\n";
print $q->br();
print $q->submit(-value => "Register Me"), "\\n";
print $q->end_form;
print $q->end_html;
In the end, the above CGI program produces the web form shown in the
figure below [Fig 2]. But what has all this extra work gained us? Well,
first off, we have at least a couple Perl scripts written that we can copy
and modify in the future to suit our needs. But more importantly, we now
have a dynamic web page. Let us say that as participants register
themselves, they are removed from the table by the form processor and
inserted into another table of registered participants. That way, the more
people that register, the shorter our list in the web form becomes. Also,
if new participants sign up, all we have to do is add their name to the
participants table and our web form is automatically updated. What
about output? We can easily generate lists of users from the tables of who
has and who hasn't registered yet. We pretty much did the former of these
in our first example, we just need to add some HTML tags to it. The point
isn't so much that we can give this data to the end user, but that
with a web form and CGI program, we can give them exactly what they
want.

Learning Curve
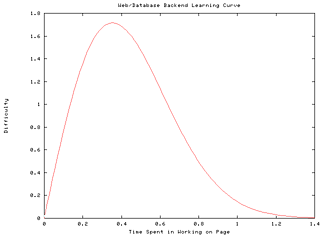
The learning curve in creating and maintaining these types of dynamic web documents is very similar to the programming/design curve for Object Oriented programming. There is an initial, high level of design and consideration for what you want to accomplish. A simple project, like the "ACM Election" example, given below, requires very little setup time. However, the "System Change Report" example required several weeks to fully plan and implement. In putting my statistics class to good use, I've observed that the Web/Database design/learning curve looks similar to a Weibull distribution, with a = 4 and ß = 2, as shown below [Fig 3]. Yes, this curve looks very intimidating, but that should not discourage you. The reason I've telling you about this is because I do not want anybody to set their expectations too high. Creating these web pages is not an easy manner, but with time and perseverance, it is achievable and there are many rewards.
Working/Example Models
Since any comprehensive examples would be very long and most probably very boring, I'm going to try to explain the key points in two systems that I have developed. Hopefully you will get some ideas or at the very least a decent understanding of what Web/Database integrated applications can do for you and your users.
Example - A.C.M. Election
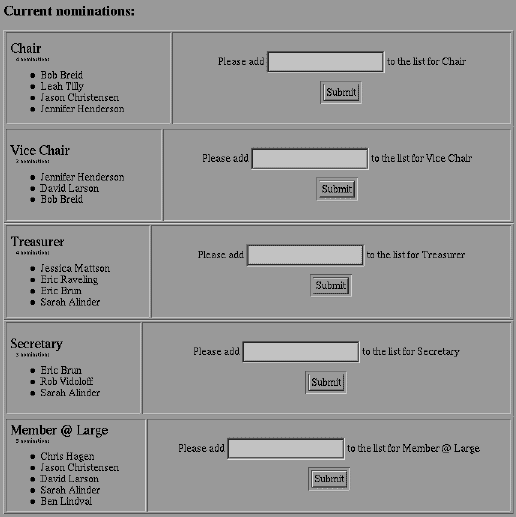
Every year, my local A.C.M. Chapter holds elections for its Executive Council. This process includes having members that are non-eligible, or not interested in holding a position, in volunteering to be on the Election Committee. That committee then collects nominations for individuals for a week or two. When nominations are no longer accepted, the committee must then start collecting absentee ballots. Then on election night, they actually count the votes. This year, I was on the Election Committee and decided to help streamline the process and also give users more anonymity by having them fill out a web form for any nominations [Fig 4] (text input fields have been replaced by underlined areas so that you can see them). Once I had this work done, I didn't need to do anything for awhile. When it came time to do absentee ballots, I created a table in my database for them, and another web form to collect the votes for me. For election night, I wrote up a Perl script to print out election ballots (although I had to count these by hand!). Again, as shown above in my 'Learning Curve' [Fig 3], I had a lot of initial work in setting up the tables and web pages, but once that was done I could add new features to the system and use the collected data in various ways very easily.
Example - System Change Report
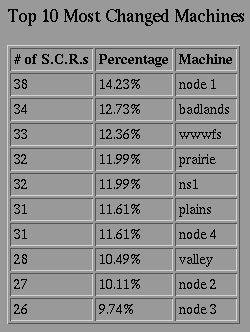
In the group that I am a part of at I.T.S., we deal with the possibility of several different system administrators making changes to the same machines and not informing each other about it. For some time now, we have employed a "System Change Report" page, which in the past would merely e-mail certain staff members or Listserv lists, post the message to some newsgroups, or send the change report to a printer. Although this system was a start, we didn't archive any of the data in a central location. It was left up to each administrator to keep track and remember any changes any other administrator made to one of the machines that they watched as well. Often, mail was deleted or lost and there was little searching ability. I spent several months, working on and off, on developing and improving a new system. In the end, I came up with the current System Change Report or S.C.R. In the new S.C.R., not only is the initial page that comes up dynamic, but all the change reports are stored in the database as well. When I designed my database schema [Fig 1], I didn't even think about any applications or searching that I would want to do. I normalized my data, set up my tables, and wrote my CGI programs. After I got all that done, I decide that I wanted a page to do searches, a page that displayed any specific change report, and a page that gave out certain interesting statistics. The development of these pages took little time, and consisted mainly of just some SQL queries and formatting the output nicely. An example of one of the statistics tables is given below [Fig 5].
Where to go next?
Obviously, using a relational database, Perl, and the above mentioned
modules isn't for everybody. The idea is that one Perl/Database savvy
person programs the templates and others fill in the data for them and make
slight changes to already existing CGI programs. I think database
technologies are really catching on. The advancements made in the freely
available databases alone over the last year are quite impressive.
PostgreSQL's feature set includes views and transactions, both of which
were unavailable on any free relational database a year ago. The MySQL
programmers are constantly adding new features and enhancements. The Perl
DBI interface has stabilized now into a virtually bug-free API. It's a
very exciting time for Web developers and administrators. I'm actually
going to go out on a limb and predict that very soon now we will see a much
tighter coupling between web servers and databases (I probably won't escape
the fact that most people that make predictions in the computer industry
look like complete idiots in usually less than two years). Whether we can
embed SQL statements right into our HTML documents with an
<SQL> tag anytime soon or not, I don't know. I do know that the
amount of information that we are all handling will increase (isn't it
always that way!) and that we will have to find solutions to deal with it.